Note: The views expressed are those of the student author and do not necessarily reflect those of the Berkman Klein Center for Internet & Society or the Applied Social Media Lab. This blog post is not a peer‑reviewed academic publication, and the empirical estimates and interpretations presented here may change as validation and review proceed.
Somewhere right now, someone is clicking “I agree” without reading a word. That’s not surprising. If the average American read the privacy policy for every website they visit, it would take about 40 minutes a day, every day for a year (McDonald & Cranor, 2008). That estimate comes from 2008, before app-based ecosystems and consolidated logins made platform dependence even more routine. The core insight, however, still holds: the rules of digital life demand more time and attention than users can realistically give. Yet billions of people routinely enter binding contracts with platforms that mediate their speech, commerce, and social lives. The terms sit in documents almost nobody reads.
The problem is not simply user negligence. Platforms govern users through Terms of Service, privacy policies, community guidelines, and moderation rules that shape what users can say, do, and contest online. Together, these documents function as systems of digital governance. Platforms can bury disclosures because users have high switching costs: the network effects that make a platform useful are the same forces that make its terms difficult to walk away from.
But there is a subtler point here. Even if users did read these documents, the language itself constructs power. A document can be short and simple while still granting the platform sweeping one-sided authority. Readability and power asymmetry are related but distinct problems. Existing transparency tools tend to focus more on readability than on how language allocates authority. This student-led research project, developed in conversation with the Transparency Hub team at the Applied Social Media Lab, tries to pull these issues apart. References to “we” and “our” throughout this post refer to the project team rather than to the Berkman Klein Center or the Applied Social Media Lab as institutions.
The Platform Asymmetry Index
Standard readability metrics such as Flesch-Kincaid or Gunning Fog answer a familiar question: How difficult is this document to understand? This project asks a different one: How does this document distribute power?
Existing transparency measures capture readability but reveal far less about whether a document concentrates authority in the platform’s favor. To address this gap, the project team developed the Platform Asymmetry Index, which breaks governance documents down along two axes. The Style Index captures how platforms communicate with users: whether through hedged language (“we may”) or directives (“users must”), who gets to define terms, and how they frame discretion. The Power Index captures what platforms claim: the degree of restrictive burden placed on users relative to the protections offered and the scope of unilateral discretion the platform reserves.
This project applies this framework to a large corpus of Terms of Service and Privacy Policies from major global platforms, including longitudinal policy histories for six platforms spanning more than fifteen years. To assess robustness, we vary the vocabulary set, adjust scoring methods, and repeatedly re-sample the corpus. The overall pattern remains stable across most specifications. Rankings shift as we vary the number of dimensions included, which underscores that modeling choices materially shape results.
Figure 1. Platform Asymmetry Index: Conceptual Framework.
Four dimensions (Complexity, Formality, Agency, Discretion) combine into two co-primary sub-indices (Style Index and Power Index) which together constitute the Platform Asymmetry Index.
What We Found
The most striking finding is not a ranking, but a pattern: platforms cluster into different governance styles. Some consistently frame governance as reciprocal: users retain agency, platforms assume defined obligations, and the language emphasizes user action. Others frame governance as unilateral: platforms “reserve the right” to act “in their sole discretion” while users “agree” and “accept.” Both approaches can satisfy formal disclosure requirements, yet they rest on fundamentally different assumptions about where authority resides.
This pattern is evident in cross-platform comparisons, but it becomes more complex at a finer level of analysis. Platform rankings do not remain consistent across document types. A platform’s position in Privacy Policies does not reliably predict its position in Terms of Service; rank correlation is close to zero. This divergence likely reflects institutional realities: different documents are shaped by distinct legal constraints, are drafted by different internal teams, and oriented toward different regulatory audiences. The typology therefore captures how platforms differ on average, not how they behave in every instance.
Figure 2. Platform Asymmetry Index Rankings with 95% Bootstrap Confidence Intervals
(n=5,000 cluster-robust bootstrap iterations; platforms anonymized A–K by rank order; †n=18 documents after data quality filtering).
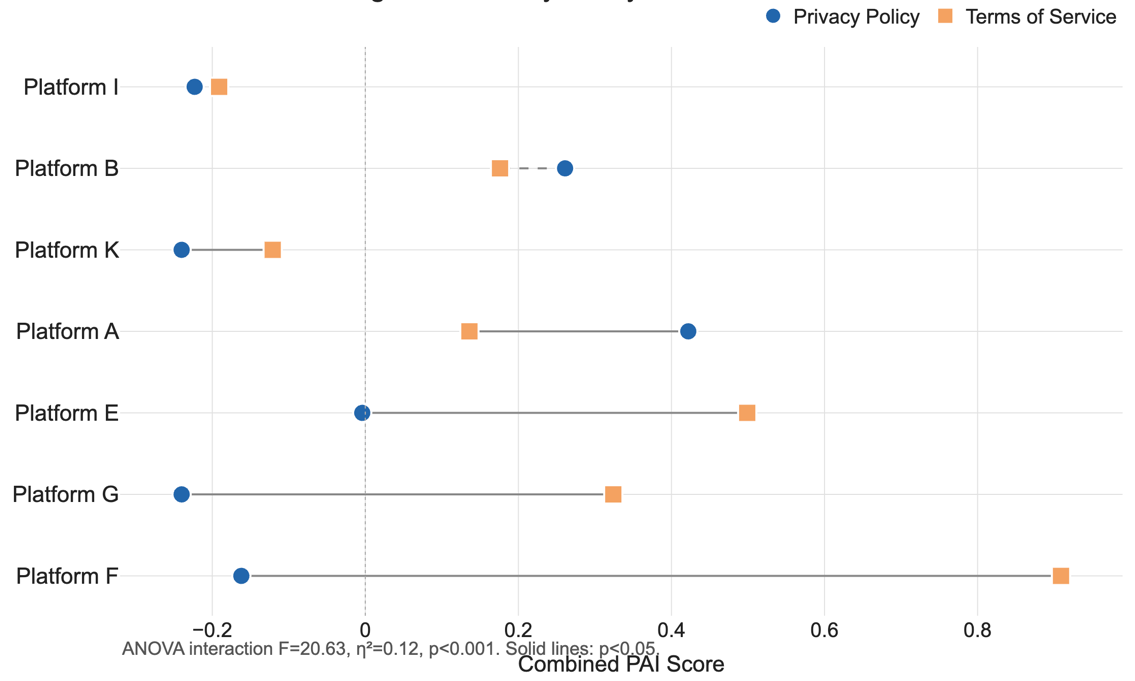
The variation does not stop there. Platforms are internally inconsistent across their own governance documents. A single platform may adopt relatively user-friendly language in its Privacy Policy while relying on strongly platform-protective terms in its Terms of Service, or vice versa. Here, “transparency” is not a stable platform-level attribute. It is a document-specific outcome, shaped by the regulatory regimes and legal risks associated with each document type. Focusing on any single document, and labeling a platform as ‘transparent’ or not, risks missing this underlying structure.
Figure 3. PAI Divergence: Privacy Policy vs. Terms of Service. Statistically significant divergence between document types. Solid lines indicate pairwise differences that reach conventional significance thresholds.
The General Data Protection Regulation (GDPR) Paradox
GDPR Article 12 requires that information be “concise, transparent, intelligible” and written in “clear and plain language.” Our baseline expectation was therefore straightforward: after 2018, policy language would become easier to understand and less asymmetrical in how it allocates discretion. In this context, “clearer” refers both to readability and reduced reliance on vague, unilateral formulations such as “we may” or “in our sole discretion.” Did this shift occur? We examine policy language pre- and post-2018 and find only weak evidence of a systematic effect. In exploratory descriptive trends, platform language is slightly more asymmetrical on our index after 2018 than before, but the difference is not statistically significant.
We refer to this as the mandatory disclosure tension. Regulations that expand disclosure obligations can increase document length and complexity mechanically. In practice, efforts to comply with a mandate to “say more” will often result in documents that are harder for users to process, even if they are more comprehensive in content.
This does not imply that disclosure mandates are ineffective. Rather, it suggests a mismatch between regulatory design and audience structure. These documents are formally addressed to individual consumers operating in high-switching-cost, concentrated digital markets—users who are unlikely to meaningfully engage with them regardless of clarity. The more relevant audiences are regulators, researchers, and civil society organizations who are better positioned to interpret these materials and translate them into accountability.
Figure 4. Combined PAI Over Time (2007-2025). Vertical dashed lines indicate GDPR announcement (2016) and enforcement (2018). Results are exploratory descriptive trends only and not interpreted as causal estimates.
A Thermometer, Not a Diagnosis
This framework has concrete applications for regulators. Data Protection Authorities enforcing GDPR Article 12 could flag platforms whose language has become more opaque over time, particularly following audits or policy updates. The European Commission’s Digital Services Act (DSA) enforcement teams could similarly use it to screen annual transparency reports for shifts in discretionary or platform-protective language. However, such metrics are not self-executing and can be gamed. For example, “We collect data” is highly legible while conveying little substantive information. Computational text analysis complements real legal review. It is a first-pass filter, not a final verdict.
Think of the Platform Asymmetry Index as a thermometer for governance language. It does not diagnose legality or intent. Instead, it identifies structural patterns: that some platforms consistently rely on power-protective formulations, that certain document types are systematically more opaque than others, and that variation across the ecosystem is patterned rather than random.
If applied longitudinally, especially alongside the Transparency Hub’s expanding archive, this approach could evolve from a research instrument into a public accountability infrastructure. The documents nobody reads are the governing text of digital life. The tools to examine them at scale are becoming available. The question is whether we will build the institutions to put them to use.
* * *
Methodological Note: One platform retains only eighteen documents after quality filtering and should therefore be treated as preliminary. Temporal analysis covers six platforms, with the most depth concentrated in two. Varying the number of dimensions in the framework shifts rankings, confirming that dimensional choices affect results. Across specifications, results remain broadly stable: vocabulary sensitivity tests yield rank correlations of ρ = 0.86–0.95, and split-half resampling produces correlations of approximately ρ ≈ 0.89–0.91 across indices. These results should be interpreted as preliminary computational baselines. A human evaluation phase involving legal experts is currently underway to validate and refine automated classifications. Final figures in the forthcoming academic version may reflect recalibration based on those assessments.